Welcome.
This is a page of a engineer's degree repository. The main clue of this engineer's is to compare the most popular technologies for a parallel computations on Intel Xeon Phi Accelerator. Feel free to fork. Repository is under Apache License.
Project description
Following project resolves the issues, in the field of Computer Science, related to parallel computing. This is a type of calculation, wherein many instructions are executed simultaneously. Currently there are multiple existing technologies, which can be used in implementation of such a model, but the purpose of this project is to compare the Message Passing Interface, Open Multi Processing and Open Computing Language on the accelerator Intel Xeon Phi 5120. The comparison was made for the three main problem areas associated with this type of computations. Those are a large number of calculations, the enormity of the data and a multitude of the communication. In order to illustrate this problem, in the context of this project, the total number of twelve applications, four for each of the mentioned areas, had been made. Among implementation there is a serial version, which was the basis used for creation of a MPI, OpenMP and OpenCL versions, so that the comparison was fair and correct. It is worth noting that in the project offload model was used, so the appropriate algorithm computations were performed only on the coprocessor side. Applications, which illustrate the problems, are performing vizualization of Mandelbrot set (a large number of simple computations), creation of an image consisting of rectangles which are generated using genetic algorithm (calculations on extensive data), and the simulation of a clientserver architecture (high intensity of communication). At the end of this paper, the results of the comparison were presented, and the best technologies, regarding selected problem areas, were pointed. Optimizations, which could complement the essence of this project, were also proposed.
Main problem areas associate with parallel computations
The main problem is excelent described in below picture.
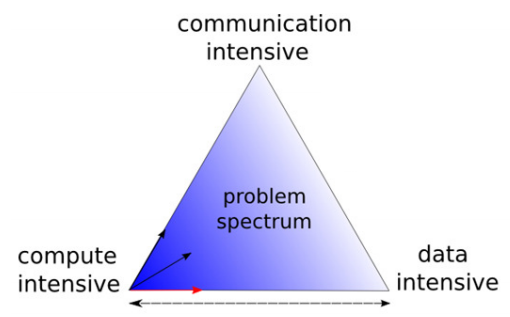
As we can see there are three main problems while writing a parallel applications. Problems with communication, with data size and computation complexity. We want to focus on these problems in the next sections.
Problem 1st 'Large number of simple computations' Mandelbrot set
The first algorithm, for which MPI, OpenMP, OpenCL technologies were compared was Mandelbrot algorithm. As we mentioned earlier. In the description and clarifications were taken into account the execution times of the entire program, including its components individually to the described technology.
MPI
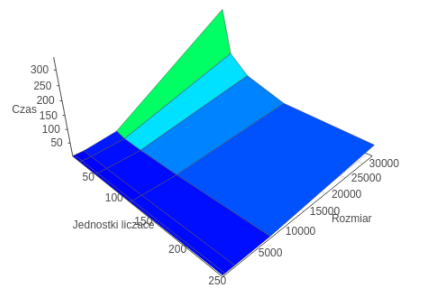
OpenMP
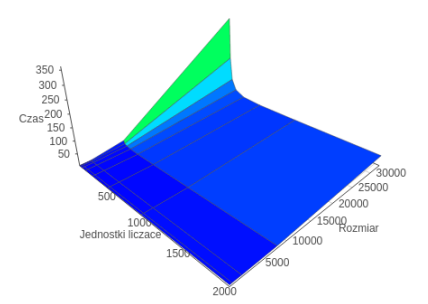
OpenCL
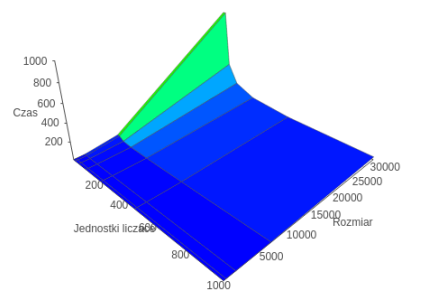
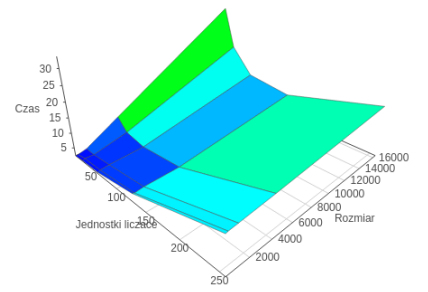
Due to the characteristics of the present discussion, that a large intensity calculations in comparison with other algorithms as implemented the best results in terms of performance have been obtained for OpenCL. This is due to the described fact that implementation of this technology rather than run the specified number of threads defined as the global size, allocates tasks to the existing 236 units working. As a result, the effect marginalized working thread context switch, as in the case of OpenMP technology. The effect is even greater in the case of MPI, which not only context is switched, but also the processes. It should be noted that the small size of the problems appears to be the best MPI. This is due to model communication between the host and the Xeon Phi coprocessor, wherein the main process communicates with each of the other nodes separately, which causes the natural overlap of computation and data transfer. This is compounded by uneven distribution of calculations for static allocation of tasks to the problem Mandelbrot. In other technologies, communication occurs only after all calculations on the coprocessor. Taking into account all the aspects of it can be concluded that for the problem of high intensity calculations, the technology OpenCL is the most optimal.
Problem 2nd 'Calculations on extensive data' Genetic algorithm
The second compared program was a genetic algorithm. As with other implementation, here also we are taken into account mainly the total execution time of the program, which was created by the following characteristics.
MPI
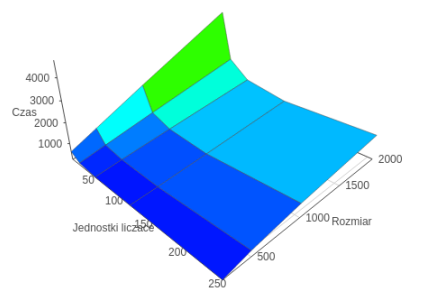
OpenMP
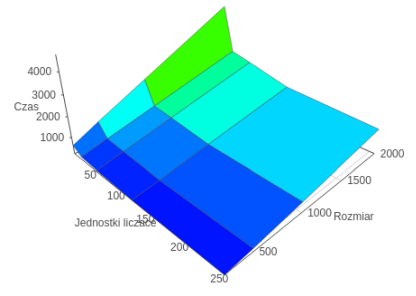
OpenCL
In the analysis of execution times environment initialization time was omitted due to the high complexity of the implemented solutions, and what follows, a long time calculations carried out within the framework of the algorithm. These comparisons were taken for the missed cache line to both levels L1 and L2. After the results obtained in the VTune, it was found that the best ratio between the memories misses at the levels L1 and L2 have OpenCL technology where this ratio was about 1 to 5, in OpenMP and MPI was at the level of 1 to 3. In comparison to Mandelbrot algorithm further enhances the technology OpenCL advantage of the greater complexity of the calculations, as well as larger data size. In contrast to the previously described Mandelbrot algorithm in this case OpenCL technology, it was also best for a small number of processes and the small size of the problem. This is due to the previously described fact that it uses the Intel Threading Building Blocks. However, for a large size of the problem and a small number of threads the best technology was OpenMP.
Problem 3rd 'High intensity of communication' ClientServer app
The last compared program was an application which focused on intensive communication between the host and the coprocessor. At the outset, it is worth noting that the analysis was based, as with other algorithms, at the time of the entire algorithm, along with communication. It should also be noted that the model used in OpenMP implementation is slightly different from that used in other technologies.
MPI
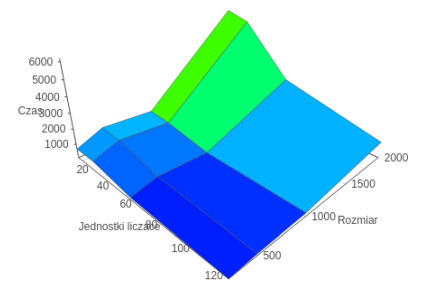
OpenMP
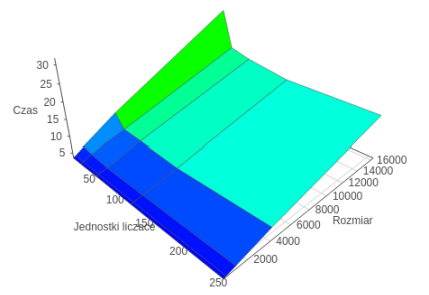
OpenCL
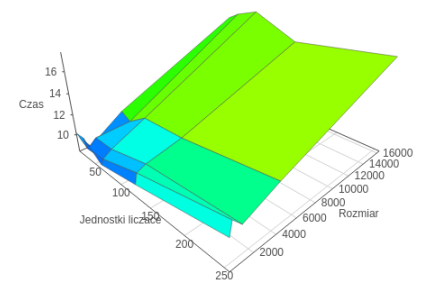
From the analysis of the measurements it came out that the Message Passing Interface technology proved to be the best, because of the attitude of communication between separate processes, which is important in the test applied to the problem of the division of labor. At one time a single process is responsible for one request while other technologies are focused on communication of low bulk granulation. Therefore, assuming a different model, which demands calculation in groups of 16 arrays, especially technology OpenCL could gain because of strong attitudes on the use of technology vectorization. It is worth noting that for a small problem the best technology is OpenMP. However, due to the use of the different model, it omitted mention of her in relation to the MPI.
Additional calculation with different settings for MIC_KMP_AFFINITY variable
Compact
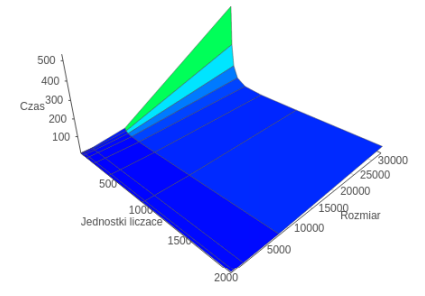
Scatter
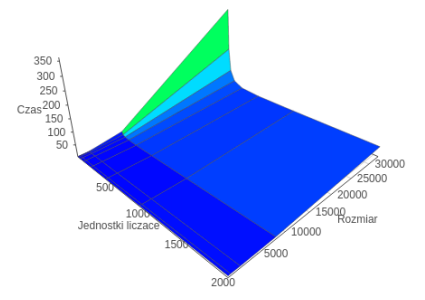
Authors
Support or Contact
Have any question? Contact us. On @MNie profile you can find email to contact.